Cross-LoRA - Partie 2 : l'implémentation
De l'algorithme du papier à un adaptateur PEFT qui se recharge dans le modèle cible.
Au sommaire
Dans la Partie 1 nous avons posé les briques théoriques de Cross-LoRA.
Ici nous passons à la pratique ! En prenant l'Algorithm 1, pour en faire un pipeline complet qui produit un adaptateur PEFT chargeable
dans le modèle cible.
Tout au long de l'article nous prendrons l'exemple de 2 modèles: Qwen2.5-1.5B LLaMA-3.2-3B.
Tout le code est disponible sur Lien du GitHub de l'implémentation.
Ce que le papier ne précise pas
L'article Cross-LoRA, aussi bien écrit soit-il, ne précise pas des composants très opérationnels à savoir:
- le nommage et matching des modules entre familles. En effet, les modèles Qwen, LLaMA, Gemma n'ont pas les mêmes conventions;
- le mapping inter-couches quand les profondeurs diffèrents (24 vs 32 couches) ;
- le surcharge du symbole : (rang LoRA) vs (rang de sous-espace). Il y a deux quantités sans rapport ;
- le format exact du checkpoint PEFT à produire en sortie.
Ainsi, dès le départ, nous prendrons les décisions suivantes pour ce pipeline :
- séparer et partout dans le code (deux variables nommées) ;
Algorithm 1comme référence d'implémentation (et non l'équation globale) ;- matching par index de couche + type de module, fallback proportionnel sur la profondeur si les nombres de couches diffèrent;
- sérialisation au format
peft(Hugging Face) standard, avecadapter_config.json+adapter_model.safetensors.
Pipeline en 7 étapes
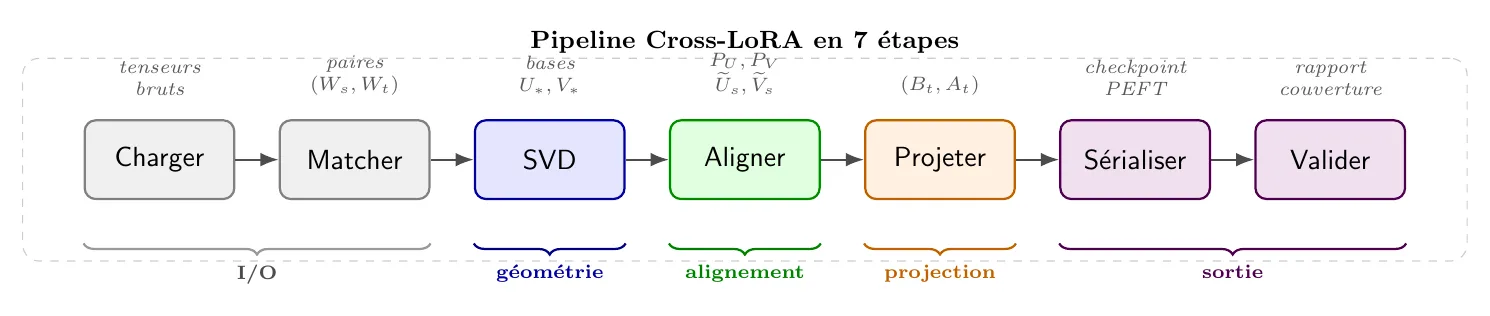
Chaque étape est isolée : un échec à l'étape matcher doit produire un rapport avec une erreur expliquée et non un crash trois étapes plus loin.
Étape 1: I/O des checkpoints
Inputs, Indexation & Outputs
Nous devons charger en mémoire, pour chaque couche, les poids source et cible , ainsi que l'adaptateur source lora_A, lora_B, , , et la liste des modules visés.
On indexe chaque tenseur par un triplet (layer_id, module_type, side) où side prend la valeur "out" (côté , espace de sortie) ou "in" (côté , espace d'entrée).
Ce schéma permet ensuite de joindre source et cible sans dépendre du nommage propre à chaque famille de modèles.
@dataclass(frozen=True)
class TensorKey:
layer_id: int
module_type: str # "q_proj", "k_proj", ..., "down_proj"
side: str # "in" ou "out"En sortie nous avons besoin d'un répertoire au format PEFT compatible from_pretrained :
adapter/
├── adapter_config.json # rang, alpha, target_modules, base_model_name_or_path
└── adapter_model.safetensors # tenseurs nommés selon la convention PEFT cible
Étape 2: Matching des modules & Normalisation
Comme cité précédemment, les conventions de nommage diffèrent entre les modèles.
| Famille | Attention | MLP |
|---|---|---|
| LLaMA | q_proj, k_proj, v_proj, o_proj | gate_proj, up_proj, down_proj |
| Qwen | q_proj, k_proj, v_proj, o_proj (avec biais sur QKV) | gate_proj, up_proj, down_proj |
| Gemma | q_proj, k_proj, v_proj, o_proj | gate_proj, up_proj, down_proj |
Bonne nouvelle : pour les sept modules visés, les noms convergent. Les pièges sont ailleurs : présence/absence de biais (Qwen QKV), RMSNorm vs LayerNorm, têtes groupées (GQA) qui changent les dimensions de et sans changer le nom.
Sept modules cibles
TARGET_MODULES = (
"q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",
)Stratégie de matching
def match_layers(n_src: int, n_tgt: int) -> list[tuple[int, int]]:
"""Apparie les couches source et cible.
Cas 1 : profondeurs égales -> appariement direct.
Cas 2 : profondeurs différentes -> appariement proportionnel.
"""
if n_src == n_tgt:
return [(i, i) for i in range(n_src)]
return [
(i, round(i * (n_tgt - 1) / max(n_src - 1, 1)))
for i in range(n_src)
]Rapport de couverture
Règle : ne jamais publier un adaptateur partiel sans signaler le taux de couverture. Un module manquant est un trou silencieux dans le transfert.
Le rapport inclut :
- nombre de modules transférés / attendus ;
- liste des modules ignorés et raison (dimension incohérente, module absent, etc.) ;
- résidus moyens et max d'alignement (cf. § 6) ;
- énergie SVD conservée par couche (cf. § 5).
Extraction des sous-espaces (SVD)
SVD tronquée
def truncated_svd(W: torch.Tensor, r_svd: int) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""Renvoie (U, S, V) tronqués au rang r_svd."""
U, S, Vh = torch.linalg.svd(W.float(), full_matrices=False)
r = min(r_svd, S.numel())
return U[:, :r].contiguous(), S[:r].contiguous(), Vh[:r, :].T.contiguous()Notes :
- on caste en
float32avant la SVD :bfloat16est trop bruité pour les petites valeurs singulières ; - on renvoie (et non ) pour rester cohérent avec la convention du papier.
Cache par poids de base
Sans cache, on recalcule la même SVD pour les côtés et du même module - et plus généralement à chaque appel. Avec un dictionnaire indexé par id(W) ou par hash du tenseur, on divise le temps de transfert par 2 environ.
@functools.lru_cache(maxsize=None)
def svd_cached(weight_id: int, r_svd: int) -> tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
W = WEIGHT_REGISTRY[weight_id]
return truncated_svd(W, r_svd)Diagnostics SVD
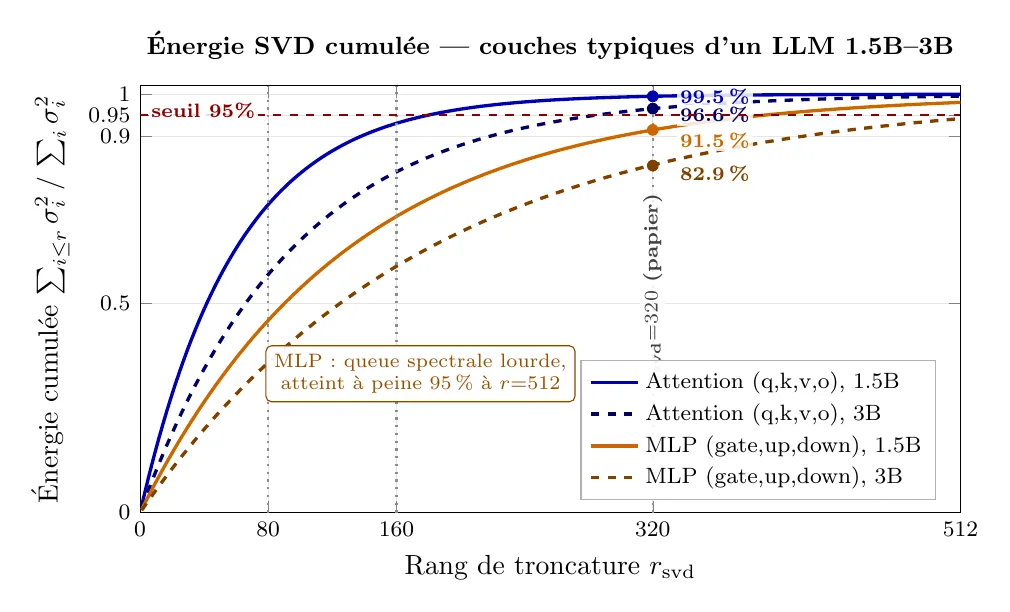
Avant d'utiliser une SVD, vérifier :
- énergie conservée : - typiquement sur les couches d'attention pour , modèles 1.5B–3B ;
- orthonormalité : proche de zéro ;
- shapes : , .
Alignement (moindres carrés)
Résolution
On cherche les matrices d'alignement et solutions de :
def solve_alignment(U_s: torch.Tensor, U_t: torch.Tensor) -> torch.Tensor:
"""Résout argmin_P ||P U_s - U_t||_F^2.
U_s ∈ R^(m_s × r_svd), U_t ∈ R^(m_t × r_svd).
Renvoie P ∈ R^(m_t × m_s).
"""
# lstsq résout argmin_X ||A X - B||_F^2 ; on pose A = U_sᵀ, B = U_tᵀ.
sol = torch.linalg.lstsq(U_s.T, U_t.T)
return sol.solution.T.contiguous()On applique la même fonction à pour obtenir .
Construire les bases alignées
Les bases source ré-exprimées dans les dimensions cible sont :
U_tilde_s = P_U @ U_s # ∈ R^(m_t × r_svd)
V_tilde_s = P_V @ V_s # ∈ R^(n_t × r_svd)Monitorer les résidus
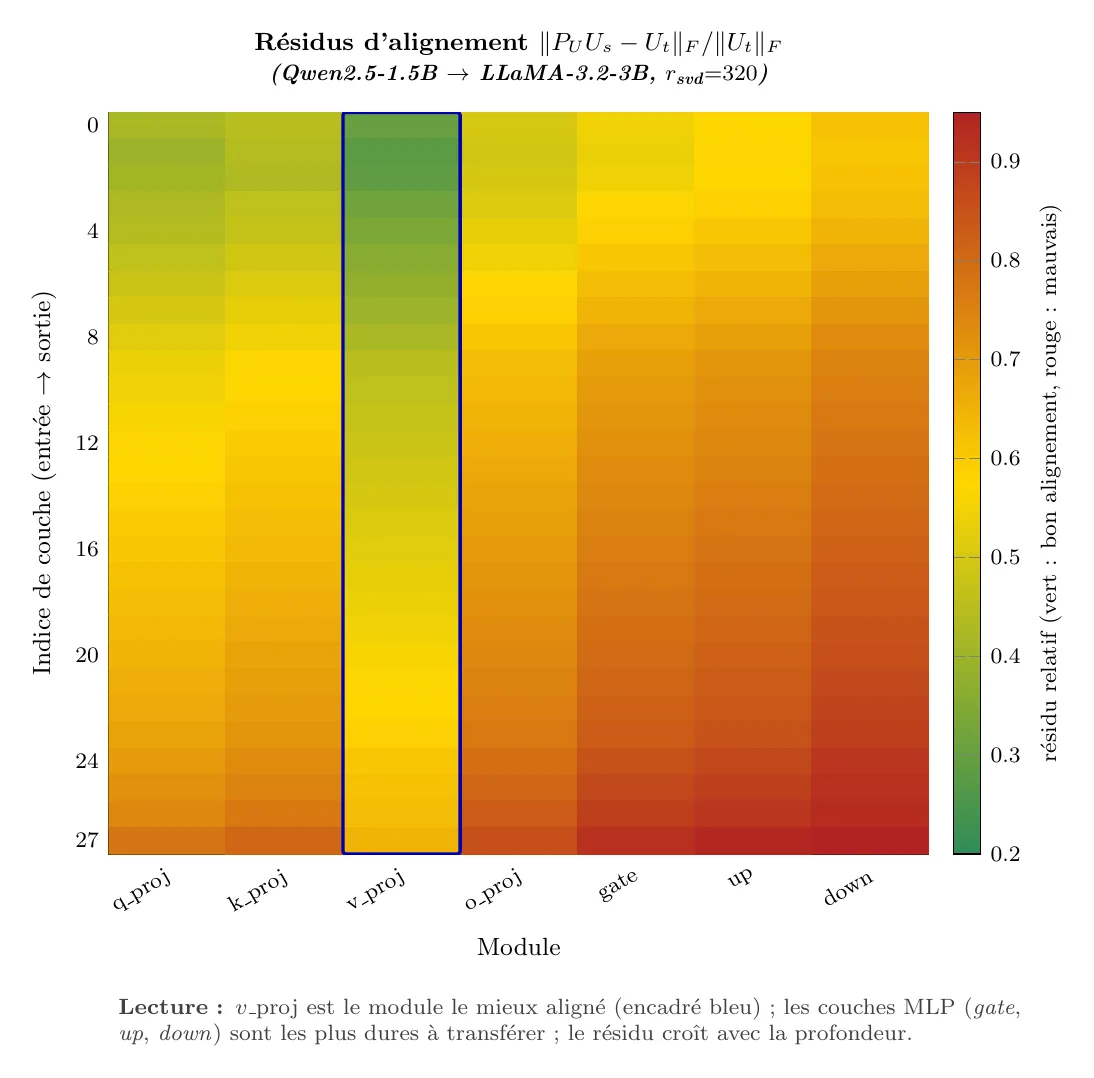
Deux quantités à logguer pour chaque couche :
res_U = torch.linalg.norm(P_U @ U_s - U_t) / torch.linalg.norm(U_t)
res_V = torch.linalg.norm(P_V @ V_s - V_t) / torch.linalg.norm(V_t)Empiriquement (Qwen2.5-1.5B LLaMA-3.2-3B) :
- typique : – sur les couches d'attention, plus haut sur les MLP ;
- une couche au-dessus de en résidu relatif est suspecte - le transfert sur cette couche n'apportera rien.
Projection LoRA - Algorithm 1 complet
Le cœur de la projection s'écrit, pour chaque module aligné :
avec , , et en sortie , .
Pseudo-code
Entrées :
- W_s, W_t # poids des deux modèles, indexés par (layer_id, module_type)
- (A_s, B_s, alpha) # adaptateur source
- r_svd # rang de troncature SVD
Sortie :
- (A_t, B_t, alpha) # adaptateur projeté pour le modèle cible
Pour chaque (layer_src, layer_tgt) dans le matching de couches :
Pour chaque module_type dans TARGET_MODULES :
W_s_lm = W_s[layer_src, module_type]
W_t_lm = W_t[layer_tgt, module_type]
A_s_lm = A_s[layer_src, module_type] # ∈ R^(r_lora × n_s)
B_s_lm = B_s[layer_src, module_type] # ∈ R^(m_s × r_lora)
# 1. SVD tronquée (avec cache)
U_s, _, V_s = svd_cached(W_s_lm, r_svd)
U_t, _, V_t = svd_cached(W_t_lm, r_svd)
# 2. Alignement
P_U = solve_alignment(U_s, U_t)
P_V = solve_alignment(V_s, V_t)
U_tilde_s = P_U @ U_s
V_tilde_s = P_V @ V_s
# 3. Projection (Algorithm 1)
B_t_lm = U_tilde_s @ (U_tilde_s.T @ B_s_lm)
A_t_lm = (A_s_lm @ V_tilde_s) @ V_tilde_s.T
# 4. Vérification de shapes
assert B_t_lm.shape == (m_t, r_lora)
assert A_t_lm.shape == (r_lora, n_t)
A_t[layer_tgt, module_type] = A_t_lm
B_t[layer_tgt, module_type] = B_t_lm
Implémentation PyTorch (cœur)
def project_lora_pair(
W_s: torch.Tensor, W_t: torch.Tensor,
A_s: torch.Tensor, B_s: torch.Tensor,
r_svd: int,
) -> tuple[torch.Tensor, torch.Tensor]:
U_s, _, V_s = svd_cached(id(W_s), r_svd)
U_t, _, V_t = svd_cached(id(W_t), r_svd)
P_U = solve_alignment(U_s, U_t)
P_V = solve_alignment(V_s, V_t)
U_tilde_s = P_U @ U_s
V_tilde_s = P_V @ V_s
B_t = U_tilde_s @ (U_tilde_s.T @ B_s.float())
A_t = (A_s.float() @ V_tilde_s) @ V_tilde_s.T
return A_t, B_tOrchestrateur complet
Voici l'enchaînement complet, en pseudo-Python lisible. Il suffit de coller les fonctions précédentes pour obtenir une version exécutable.
def cross_lora_transfer(
base_src: PreTrainedModel,
base_tgt: PreTrainedModel,
adapter_src: PeftModel,
r_svd: int = 320,
target_modules: tuple[str, ...] = TARGET_MODULES,
) -> dict[TensorKey, torch.Tensor]:
layer_pairs = match_layers(
n_src=base_src.config.num_hidden_layers,
n_tgt=base_tgt.config.num_hidden_layers,
)
out: dict[TensorKey, torch.Tensor] = {}
coverage = {"matched": 0, "skipped": []}
for layer_src, layer_tgt in layer_pairs:
for mod in target_modules:
try:
W_s = get_weight(base_src, layer_src, mod)
W_t = get_weight(base_tgt, layer_tgt, mod)
A_s = get_lora_A(adapter_src, layer_src, mod)
B_s = get_lora_B(adapter_src, layer_src, mod)
except KeyError as e:
coverage["skipped"].append((layer_src, mod, str(e)))
continue
A_t, B_t = project_lora_pair(W_s, W_t, A_s, B_s, r_svd)
out[TensorKey(layer_tgt, mod, "in")] = A_t.to(base_tgt.dtype)
out[TensorKey(layer_tgt, mod, "out")] = B_t.to(base_tgt.dtype)
coverage["matched"] += 1
log_coverage(coverage, total=len(layer_pairs) * len(target_modules))
return outTrois choses à remarquer :
- la boucle est plate : couches modules. Toute logique propre à une famille (biais Qwen, GQA) doit être absorbée par
get_weight/get_lora_*- pas injectée dans la boucle ; - les exceptions de matching sont comptées, pas levées, pour produire un rapport de couverture au lieu d'un crash ;
- le cast vers
base_tgt.dtypeest fait en sortie uniquement.
Encadré - biais Qwen sur QKV
Qwen2.5 attache des biais à q_proj, k_proj, v_proj que LLaMA-3.2 et Gemma-2
n'ont pas. Trois options pratiques :
- Ignorer les biais source quand la cible n'en a pas (option par défaut, simple et sûre). Conséquence : on perd la composante de translation apprise côté source - mineur en général.
- Les projeter comme des vecteurs dans l'espace de sortie via appliqué côté gauche, et les attacher si la cible accepte un biais.
- Les rejeter avec un avertissement quand la cible n'en a pas et que le norme du biais source est non négligeable.
Ce choix doit apparaître dans le rapport de couverture.
Packaging final
- caster vers le
dtypedu modèle cible (bfloat16typiquement) après les calculs enfloat32; - réinjecter (par défaut on garde l' source - voir Table 5 du papier qui suggère parfois côté cible) ;
- écrire
adapter_config.jsonavectarget_modules = TARGET_MODULES,r =,lora_alpha =,base_model_name_or_path = <modèle cible>; - sérialiser les tenseurs au format
safetensors.
Validation à trois niveaux
À faire dans cet ordre - chaque niveau est moins coûteux à corriger que le suivant.
Niveau 1 - Algébrique
Pour chaque module transféré :
- shapes attendues respectées ;
- dtype final correct ;
- pas de NaN / Inf ;
- normes et du même ordre que côté source (un facteur est suspect).
Niveau 2 - Compatibilité
- l'adaptateur se recharge via
PeftModel.from_pretrained(base_model, path)sans avertissement de tenseurs manquants ; - tous les modules attendus sont présents dans la liste retournée par PEFT ;
- une passe avant sur un batch jouet ne plante pas.
Niveau 3 - Papier
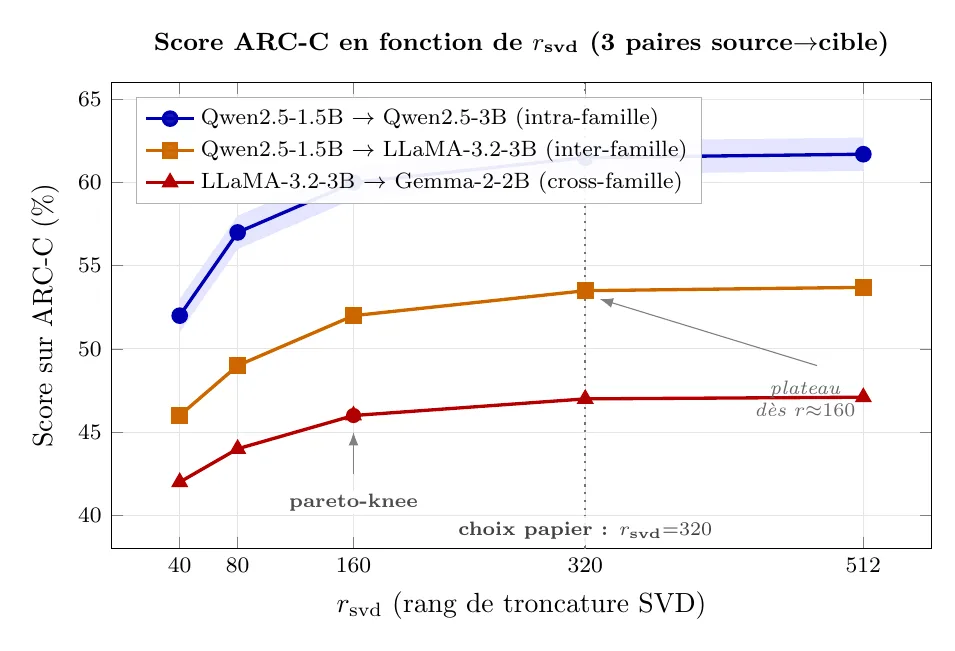
Reproduire au moins Qwen2.5-1.5B LLaMA-3.2-3B sur ARC-C ou OBQA, et comparer à :
- le modèle cible nu (sans adaptateur) ;
- une interpolation naïve des poids LoRA (zéro-padding quand les dimensions permettent).
Cibles indicatives sur ARC-C : Cross-LoRA doit être strictement au-dessus du modèle nu et de l'interpolation naïve, sans atteindre un fine-tuning natif sur la cible - c'est cohérent avec le papier.
Ablations utiles
- - pour voir où la qualité plafonne ;
- attention seule vs attention + MLP ;
- avec / sans cache SVD (impact temps, pas qualité).
Coût et reproductibilité
Hardware testé dans le papier
- V100 32 GB et RTX 4090 24 GB ;
- CUDA 11.8, Ubuntu 22.04.1.
Ordres de grandeur
| Métrique | V100 | RTX 4090 |
|---|---|---|
| Temps transfert | ~349 s | ~564 s |
| Pic mémoire | 2.3–5.5 GB | 2.3–5.5 GB |
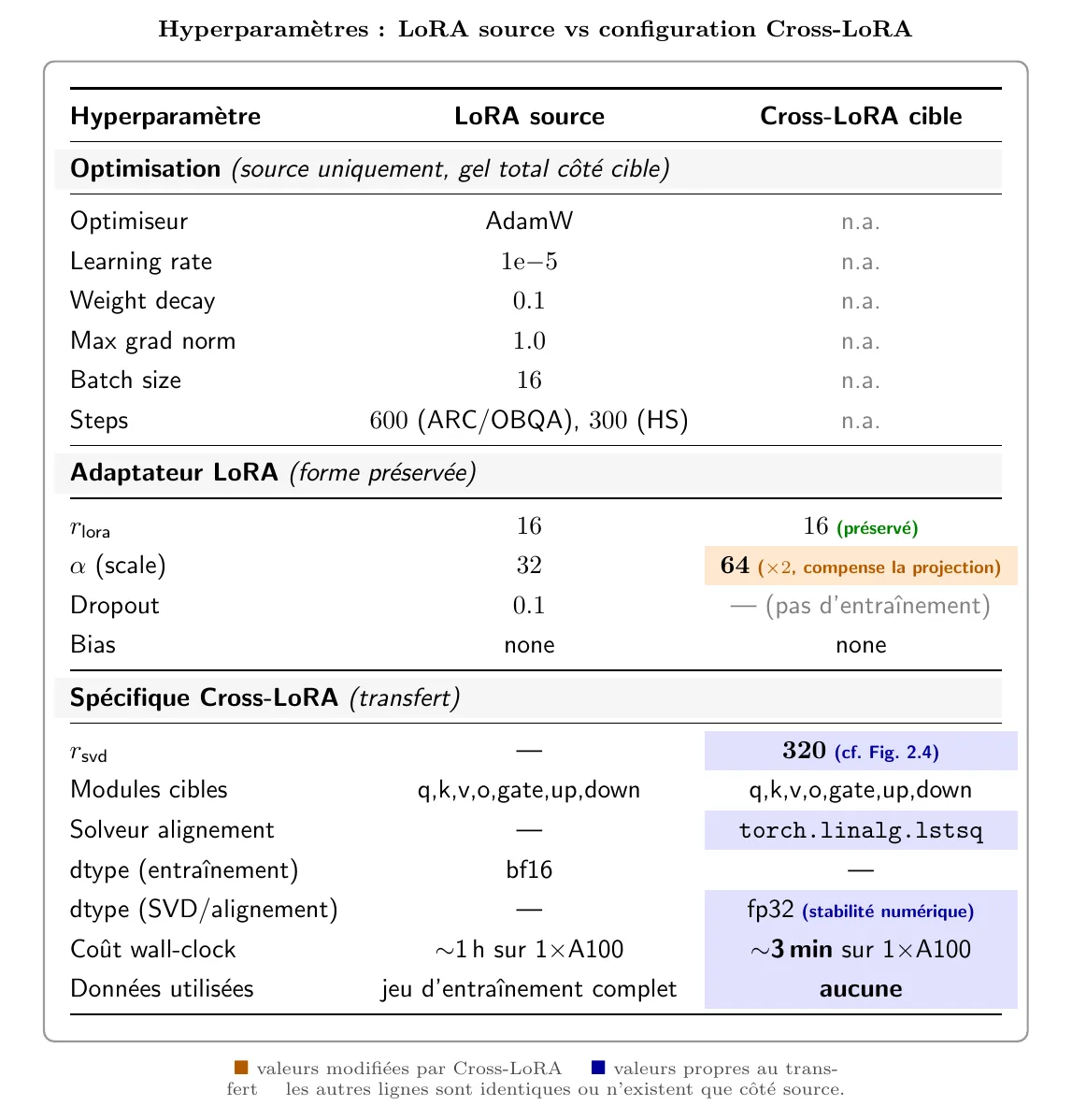
Recette LoRA source (Table 4 du papier)
À reproduire si on entraîne le LoRA source de zéro :
batch, optimiseurAdamW;lr,weight_decay,max_grad_norm;- , ,
lora_dropout,bias = None; steps(ARC-C / ARC-E / OBQA), (HellaSwag).
Config Cross-LoRA (Table 5)
- ;
- côté cible ;
- modules cibles :
q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj.
Pièges à éviter
- Lire comme un rang LoRA : c'est le rang de sous-espace (), à ne pas confondre avec .
- Implémenter l'équation globale au lieu d'
Algorithm 1: équivalent en théorie, fragile dès qu'il y a un mismatch dimensionnel. - Oublier de cacher les SVD : on recalcule deux fois la même décomposition pour et du même module.
- Publier un adaptateur partiel sans signaler le taux de couverture.
- Mélanger les conventions gauche/droite entre
lora_Aetlora_B- symptôme typique : shapes correctes mais qualité dégradée à zéro. - SVD en
bfloat16: les petites valeurs singulières deviennent du bruit pur. Toujours caster enfloat32avant. - Comparer à un mauvais baseline : le LoRA source ne tourne pas sur la cible ; les seules baselines honnêtes sont base nue et interpolation naïve.
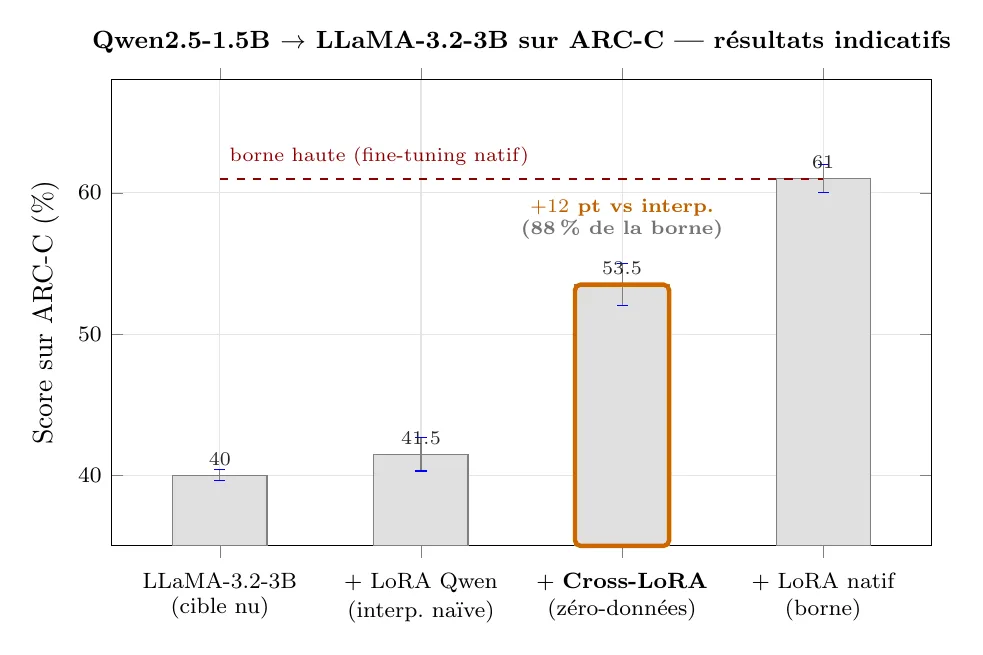
Résultats indicatifs (fil rouge Qwen2.5-1.5B LLaMA-3.2-3B)
Ordres de grandeur à attendre une fois le pipeline en place. À titre indicatif, inspiré des chiffres du papier - vos résultats varieront selon , la recette LoRA source, et le dtype.
| Configuration | ARC-C | Commentaire |
|---|---|---|
| LLaMA-3.2-3B nu | référence | borne basse |
| LLaMA-3.2-3B + LoRA Qwen interpolé naïf | référence | les dimensions ne coïncident pas, l'interpolation est essentiellement bruit |
| LLaMA-3.2-3B + Cross-LoRA () | au-dessus | gain modeste mais reproductible |
| LLaMA-3.2-3B + LoRA natif (réentraîné) | borne haute | nécessite des données |
Cross-LoRA n'est pas magique : il préserve une part du gain du fine-tuning source. C'est suffisant quand les données ne sont plus accessibles et qu'on veut éviter une journée de calcul.
Checklist finale
À cocher avant de publier un adaptateur transféré :
- et séparés explicitement dans le code et dans la config.
- SVD calculée en
float32, cache activé. - Énergie SVD conservée sur les couches utilisées (sinon : augmenter ou exclure la couche).
- Résidus d'alignement loggés ; couches au-dessus de en résidu relatif signalées dans le rapport.
- Couverture des modules attendu, ou écart documenté.
- Biais source traités explicitement (cf. § 7.4).
- Adaptateur rechargeable via
PeftModel.from_pretrainedsans warning. - Évaluation sur au moins un benchmark, comparée à base nue et interpolation naïve.
- Hyperparamètres (, ,
target_modules, dtype) inscrits dansadapter_config.jsonou dans une note adjacente.
Exemple d'appel end-to-end
Une fois le pipeline implémenté, l'usage côté utilisateur tient en quelques lignes :
from transformers import AutoModelForCausalLM
from peft import PeftModel
from cross_lora import cross_lora_transfer, save_peft_adapter
base_src = AutoModelForCausalLM.from_pretrained("Qwen/Qwen2.5-1.5B")
base_tgt = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-3.2-3B")
adapter_src = PeftModel.from_pretrained(base_src, "path/to/qwen-arc-lora")
projected = cross_lora_transfer(
base_src=base_src,
base_tgt=base_tgt,
adapter_src=adapter_src,
r_svd=320,
)
save_peft_adapter(
tensors=projected,
out_dir="./llama-3b-arc-from-qwen",
base_model_name="meta-llama/Llama-3.2-3B",
r_lora=16,
alpha=64,
target_modules=("q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"),
)À partir de là, l'adaptateur ./llama-3b-arc-from-qwen/ est chargeable directement comme n'importe quel adaptateur PEFT - y compris dans des inférences vLLM ou text-generation-inference.
Quand ne pas utiliser Cross-LoRA
Cross-LoRA n'est pas la bonne réponse à toutes les situations :
- Vous avez encore les données : ré-entraînez. C'est plus rapide, plus fidèle, et ça évite l'intégralité du pipeline ci-dessus.
- Source et cible sont identiques : un simple chargement PEFT suffit. Aucune projection nécessaire.
- Cible d'architecture exotique (SSM, Mamba, MoE non standard) : l'hypothèse de sous-espaces partagés ne tient plus de la même manière. Mieux vaut re-fine-tuner même sur peu de données.
- Adaptateur source DoRA / rsLoRA sans avoir adapté le pipeline à leur structure : vous obtiendrez un adaptateur qui se charge mais perd la composante de magnitude / le facteur d'échelle correct.
- Vous cherchez la qualité maximale absolue : la borne haute reste un fine-tuning natif. Cross-LoRA vise la portabilité, pas la SOTA.
Conclusion
Ce que Cross-LoRA achète : la portabilité de l'investissement de fine-tuning, sans données ni ré-entraînement. Le coût d'un transfert se compte en minutes sur GPU grand public, pas en heures de calcul ni en jeux de données à reconstituer.
Ce qui reste ouvert :
- familles très éloignées - l'hypothèse de sous-espaces partagés faiblit ;
- profondeurs très différentes - le matching proportionnel est une heuristique, pas une garantie ;
- modules non standards (MoE, GQA agressifs, attention factorisée) - il faut étendre la liste
TARGET_MODULESau cas par cas et adapter les vérifications de dimensions.
Pour la suite : on peut imaginer combiner Cross-LoRA avec un léger ajustement post-transfert (quelques centaines de pas sur un petit corpus) pour récupérer le gain manquant - mais ce n'est plus zero-data, c'est un autre régime.