Cross-LoRA - Partie 1 : la théorie
Transférer un adaptateur LoRA d'un modèle à un autre, sans données et sans ré-entraînement.
Au sommaire
Les modèles de base évoluent vite. Lorsque vous avez investi du temps et des données pour entraîner un LoRA sur un modèle, vous voulez idéalement pouvoir le réutiliser sur un autre modèle, sans avoir à ré-ajuster le LoRA lui-même.
C'est tout l'objet du papier Cross-LoRA: A Data-Free LoRA Transfer Framework across Heterogeneous LLMs.
TL;DR - Cross-LoRA prend un adaptateur LoRA entraîné sur un modèle source, fait une SVD tronquée des poids des deux modèles, aligne les bases par moindres carrés, puis projette et côté droit et côté gauche pour obtenir un adaptateur directement attachable au modèle cible. Aucune donnée et aucun gradient n'est requis, seulement quelques minutes GPU par couple de modèles.
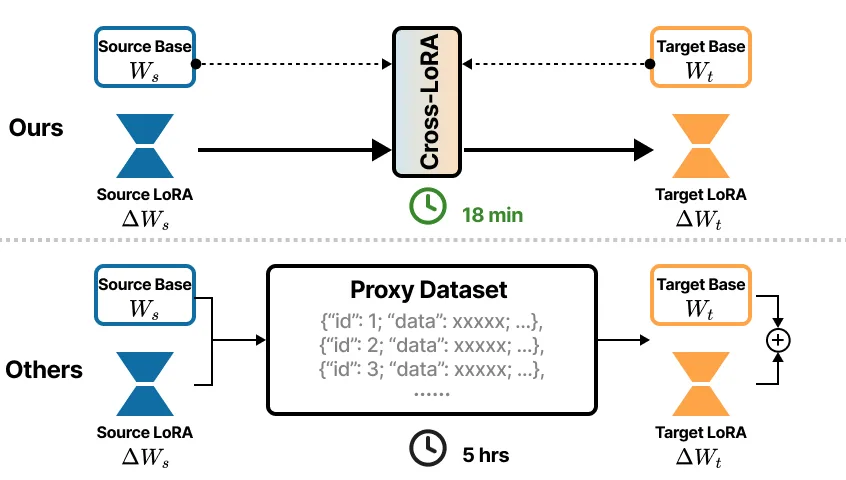
Cette série est découpée en deux articles :
- Partie 1 - la théorie (cet article) : pourquoi le transfert zero-data est possible, et comment il fonctionne sur le papier.
- Partie 2 - l'implémentation : comment passer de l'algorithme à un adaptateur PEFT qui se charge réellement dans le modèle cible.
Dans cet article, nous apprendrons:
- Pourquoi un adpatateur LoRA n'est pas portable par défaut,
- Qu'est ce que Cross-LoRA:
- comment ça fonctionne: le contenu exact d'Algorithm 1 du papier
- Quels hypothèses à la méthode et comment les vérifier
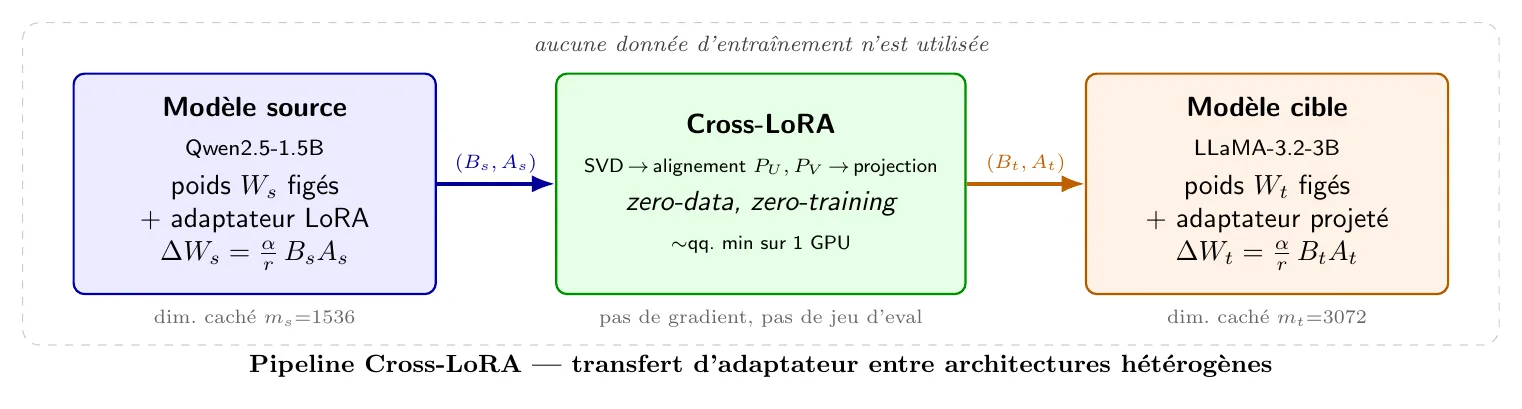
Table des notations
Dans le reste des articles nous utiliserons les notations suivantes:
| Symbole | Sens | Exemple typique |
|---|---|---|
| , | poids d'une même couche dans le modèle source / cible | matrice |
| dimensions de sortie / entrée côté source | ||
| dimensions de sortie / entrée côté cible | ||
| mise à jour LoRA () | rang | |
| rang LoRA - typiquement petit | , , | |
| , | facteurs LoRA, , | |
| rang de troncature de la SVD - rien à voir avec | , | |
| SVD tronquée de : | ||
| matrices d'alignement des bases source vers cible | obtenues par | |
| bases source ré-exprimées dans les dimensions cible |
Convention : on écrit pour la transposée. pour la norme de Frobenius, et pour l'opérateur de minimiseur d'un problème de moindres carrés.
LoRA : Rappel et Problème
Le principe
LoRA part d'une observation empirique : quand on fine-tune un grand modèle, la mise à jour qu'on applique aux poids est de rang effectif faible. Autrement dit, on n'a pas besoin d'une matrice pleine pour capturer ce que le fine-tuning veut exprimer - une matrice de rang suffit, avec .
LoRA exploite ça en figeant et en n'apprenant que deux petites matrices :
À l'inférence, la couche calcule :
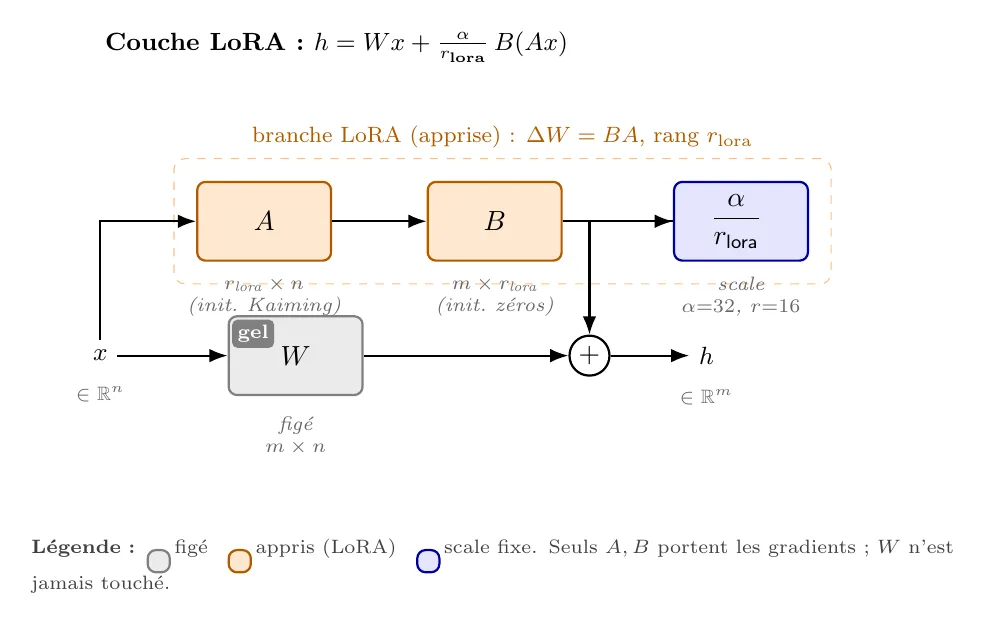
Trois conséquences utiles pour la suite
- vit dans un sous-espace de dimension . Côté entrée, son image est contrainte par les lignes de ; côté sortie, par les colonnes de . C'est exactement la structure que Cross-LoRA va exploiter.
- Convention gauche / droite. agit « à gauche » (espace de sortie de la couche) et agit « à droite » (espace d'entrée). Cette dissymétrie n'est pas cosmétique : la projection Cross-LoRA traite et séparément, parce qu'ils vivent dans deux espaces différents du modèle.
- est figé. C'est ce qui rend l'idée du transfert plausible : n'a pas été tordu par le fine-tuning, ses sous-espaces dominants restent ceux du modèle de base - et donc comparables entre source et cible.
C'est ce dernier point qui ouvre la porte à Cross-LoRA : si et partagent une géométrie suffisamment proche dans leurs sous-espaces dominants, alors un exprimé dans cette géométrie devrait pouvoir être réexprimé dans celle de .
Notre problème : les LoRA ne sont pas transférables par nature
Un adaptateur LoRA est dépendant du modèle sur lequel il a été entraîné.
Il a été ajusté contre un modèle de base précis : un jeu de poids , des dimensions cachées spécifiques, une organisation de couches donnée. La paire que vous obtenez à la fin du fine-tuning ne décrit pas une « compétence » portable - elle décrit une correction à appliquer à ce modèle de base, et à aucun autre.
Or les modèles de base bougent vite. Une nouvelle version de Qwen sort, LLaMA passe à une variante 3.2, Gemma publie une nouvelle famille. Chaque fois, les LoRA accumulés deviennent inutilisables tels quels.
Les options classiques sont toutes coûteuses :
- ré-entraîner le LoRA sur le nouveau modèle - il faut redisposer des données, qui ont parfois disparu, été interdites, ou simplement été utilisées sous licence expirée ;
- distiller - cela suppose des données de référence et un budget de calcul ;
- maintenir N LoRA en parallèle pour N modèles - l'effort est multiplié.
Cross-LoRA propose un troisième chemin : transférer un LoRA vers un modèle hétérogène, sans données et sans nouvelle phase d'entraînement. Le seul matériau utilisé, ce sont les poids des deux modèles de base et l'adaptateur source.
Pour clarifier ce que ça n'est pas :
- ce n'est pas une distillation : aucun modèle ne génère de réponses à imiter ;
- ce n'est pas du model merging : on ne fusionne pas deux modèles, on déplace un delta d'un modèle à l'autre ;
- ce n'est pas du fine-tuning : il n'y a pas de gradient, pas d'optimiseur, pas de fonction de perte.
C'est, littéralement, un changement de repère algébrique appliqué à .
L'intuition Cross-LoRA en une image
Voilà le raisonnement, en trois temps.
Premier temps - exposer la géométrie. Une matrice de poids se décompose en SVD : . Les colonnes de forment une base orthonormée de l'espace de sortie ; celles de , une base orthonormée de l'espace d'entrée ; dit quelles directions portent l'essentiel du signal. En tronquant à directions, on obtient une description compacte de la géométrie dominante de la couche.
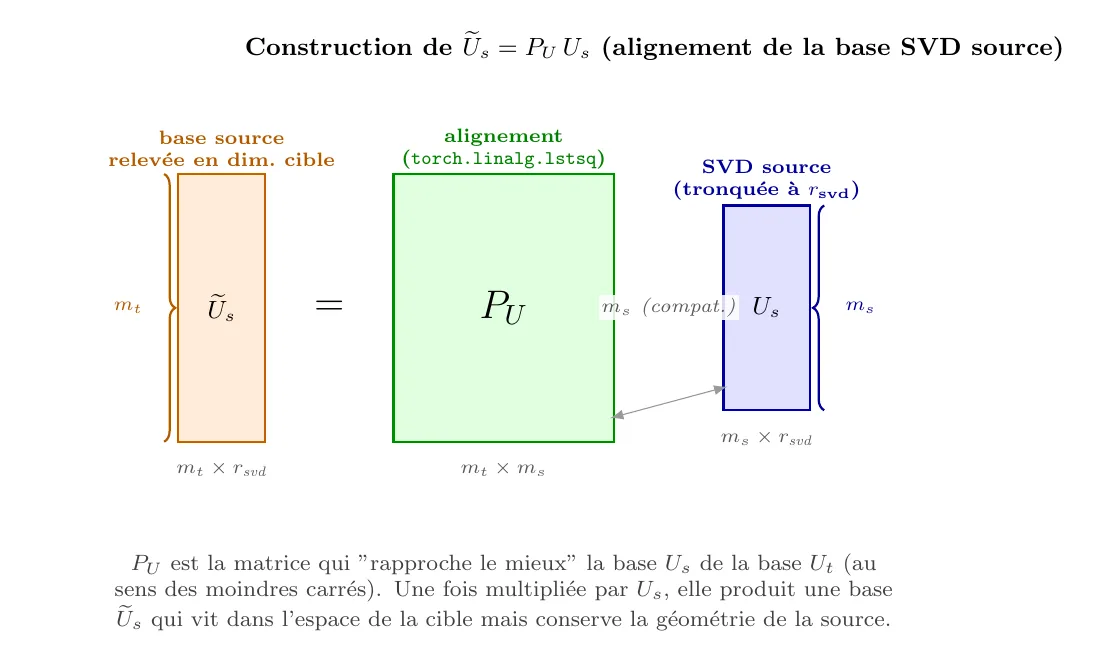
Deuxième temps - aligner. On fait la SVD du modèle source et du modèle cible. On obtient et . Ces bases ne sont pas alignées : même si elles décrivent des couches qui font « la même chose » sémantiquement, leurs axes ne pointent pas dans le même sens. On cherche donc une transformation qui amène « le plus près possible » de , et de même pour . C'est un problème de moindres carrés.
Troisième temps - projeter. Une fois les bases alignées, on dispose d'un dictionnaire qui dit comment exprimer une direction de l'espace source dans l'espace cible. On l'applique à pour obtenir .
Schéma directeur : SVD alignement projection.
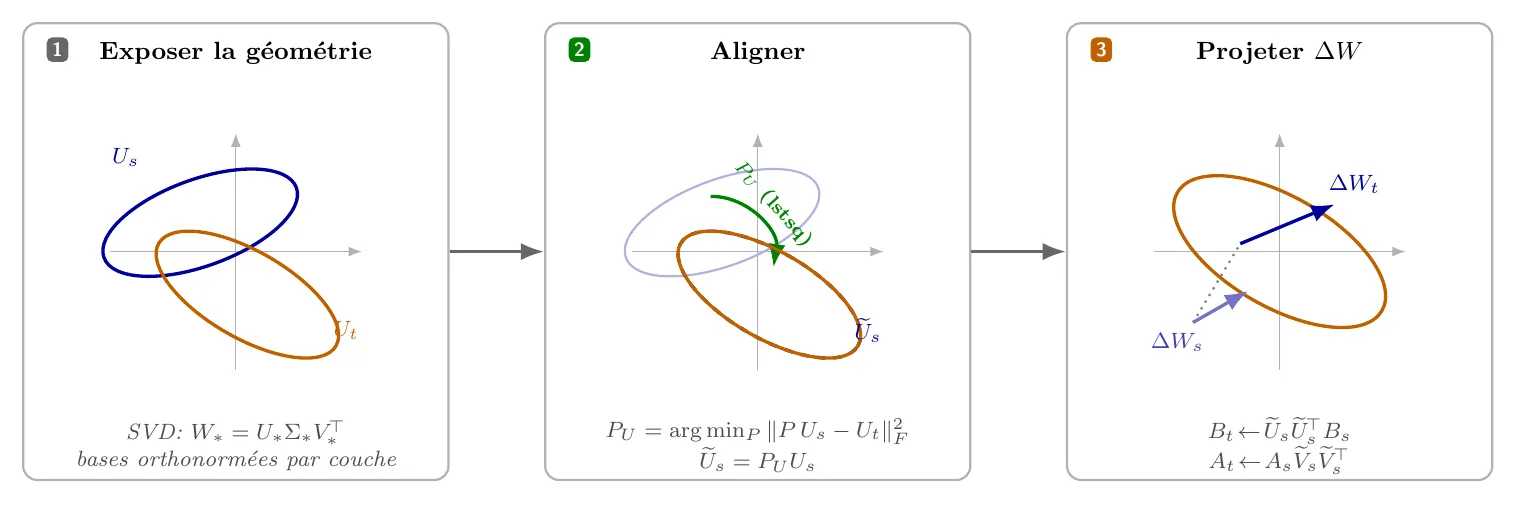
Le reste de l'article remplit les détails de chaque étape.
Brique 1 - LoRA-Align
LoRA-Align répond à une seule question : comment exprimer le repère du modèle source dans le repère du modèle cible ?
SVD tronquée
Pour chaque couche concernée, on calcule une SVD tronquée à l'ordre :
Pourquoi tronquer ?
- Coût : une SVD pleine sur une matrice de plusieurs milliers de lignes par plusieurs milliers de colonnes est lente et inutile - on ne se sert que des premières directions.
- Bruit : les directions de très petites valeurs singulières capturent surtout du bruit numérique. Les jeter améliore l'alignement plus qu'il ne le dégrade.
- Énergie retenue : suffit en pratique à conserver l'essentiel du signal des couches d'attention et MLP des modèles 1.5B–3B testés dans le papier.
Encadré - piège de notation Ce n'a rien à voir avec . Le papier utilise le même symbole pour les deux et c'est trompeur. Dans toute la série, on les garde séparés : désigne le rang LoRA (typiquement 8–32), désigne le rang de troncature de la SVD (typiquement 80–320).
Le problème d'alignement
et sont deux bases orthonormées du même type d'espace (sortie de la couche), mais « tournées » différemment, et de surcroît dans des dimensions différentes ( vs ). On cherche la transformation qui les recolle :
C'est un problème classique de moindres carrés. Le papier utilise
torch.linalg.lstsq, qui le résout par décomposition QR ou SVD selon le solveur.
Remarque - pourquoi pas Procrustes ? On pourrait être tenté de chercher orthogonal et résoudre un problème de Procrustes orthogonal. Cross-LoRA ne le fait pas : il accepte des non orthogonaux, ce qui laisse de la flexibilité quand ou - précisément le cas hétérogène qui motive la méthode.
Bases alignées
À la sortie de cette étape, on dispose de :
est une base du sous-espace dominant source, mais ré-exprimée dans les dimensions du modèle cible. C'est exactement le dictionnaire dont on avait besoin.
Brique 2 - LoRA-Shift
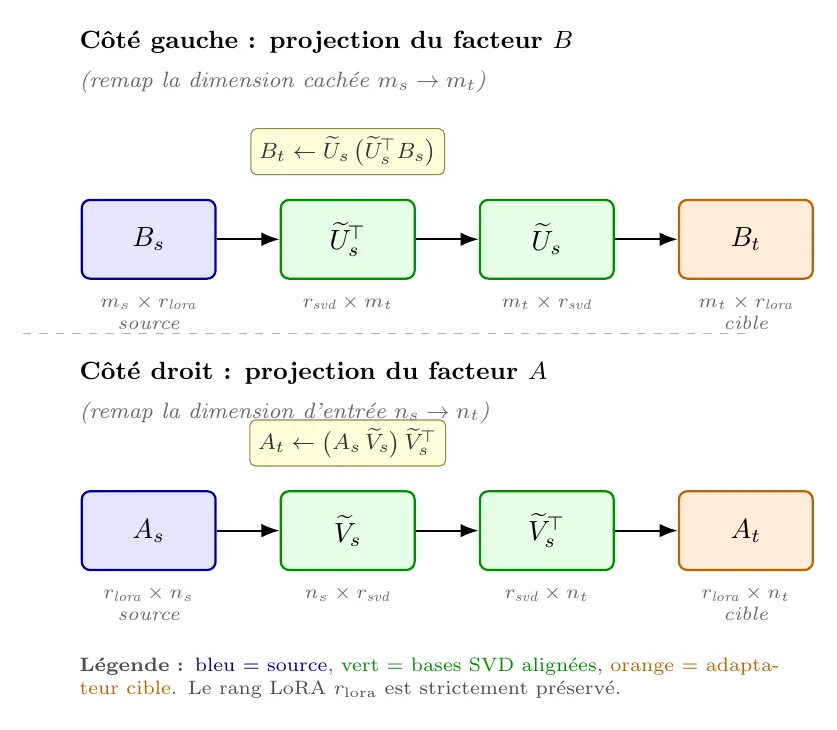
LoRA-Align nous a donné les bases alignées. LoRA-Shift les utilise pour déplacer la mise à jour LoRA elle-même.
Le papier propose une équation globale qui projette « des deux côtés à la fois ». En pratique, dès qu'il y a un mismatch dimensionnel entre source et cible, cette équation devient pénible à manipuler. L'Algorithm 1 du papier est plus propre et c'est lui qu'il faut suivre : il sépare le traitement des poids (côté gauche) et (côté droit).
Pourquoi séparer gauche et droite
Rappel : dans un module LoRA, agit dans l'espace de sortie de la couche, dans l'espace d'entrée. Ces deux espaces n'ont aucune raison d'avoir la même dimension - et entre familles hétérogènes, ils ne l'ont en général pas. Forcer une projection symétrique mélangerait deux problèmes d'alignement indépendants. Mieux vaut les traiter séparément, chacun avec sa propre base.
Les deux projections
Lecture intuitive :
- côté , on comprime dans le sous-espace dominant source via , puis on le réexprime dans les coordonnées cibles via . La composition agit comme un projecteur , mais exprimé dans le repère cible ;
- côté , c'est la même mécanique appliquée à droite avec .
Encadré - vérification de dimensions
On retrouve bien des facteurs aux dimensions du modèle cible et toujours de rang .
Ce qu'on obtient
À la fin, on a une nouvelle paire qui :
- a les bonnes dimensions pour s'attacher au modèle cible ;
- conserve la structure rang- de l'adaptateur original (la projection ne l'augmente pas) ;
- vit dans la géométrie dominante du modèle cible, telle que vue à travers l'alignement avec celle de la source.
C'est tout ce qu'on a besoin de sérialiser comme adaptateur PEFT cible.
Pourquoi ça marche (et quand ça casse)
Cross-LoRA repose sur une hypothèse forte mais raisonnable : les sous-espaces dominants des poids de deux LLM modernes pré-entraînés sur des corpus comparables capturent des structures linguistiques voisines. Pas identiques - voisines. Assez voisines pour qu'une transformation linéaire les recolle.
Cette hypothèse n'est pas gratuite. Plusieurs travaux antérieurs sur la représentation des LLM montrent que les couches d'attention et de feed-forward, malgré des initialisations et des familles différentes, convergent vers des sous-espaces fonctionnellement proches. Cross-LoRA en tire les conséquences pratiques.
Mais l'hypothèse a des limites prévisibles :
- Familles trop éloignées : entre une famille decoder-only récente et un modèle d'architecture significativement différente, la géométrie partagée s'effrite.
- Profondeurs différentes : si la source a 24 couches et la cible 32, le matching par index de couche est forcément approximatif. Le papier reste discret sur ce cas.
- Modules absents ou renommés : entre LLaMA et Gemma, les noms et le découpage des blocs MLP diffèrent. Tout module non matché est un trou dans le transfert.
- Petits rangs LoRA, grands : si est très petit, l'information utile tient dans très peu de directions. Les directions choisies par la SVD ne sont pas garanties d'être les bonnes.
Vis-à-vis des alternatives :
- l'interpolation naïve (copier les poids LoRA tels quels en zéro-paddant) fonctionne uniquement quand les dimensions coïncident, et ignore complètement la rotation entre repères ;
- le ré-entraînement reste la baseline imbattable en qualité, mais coûte des données et du calcul - exactement ce que Cross-LoRA cherche à éviter.
Cross-LoRA se positionne donc comme un compromis : moins fidèle qu'un ré-entraînement, beaucoup plus solide qu'une copie naïve, et utilisable quand on n'a plus accès aux données.
Une hypothèse à l'épreuve des faits
L'argument central - « deux LLM modernes partagent une géométrie dominante » - n'est pas un coup de chance. Plusieurs lignes de travaux antérieurs convergent :
- Représentations linéairement comparables : on sait depuis un bon moment que des modèles entraînés indépendamment sur des corpus comparables apprennent des représentations qu'une transformation linéaire suffit souvent à recoller. C'est précisément la classe de transformations que produit.
- Sous-espaces dominants stables : sur les couches d'attention et de feed-forward des LLM modernes, l'essentiel de l'« énergie » des poids tient dans une fraction des directions singulières - typiquement quelques centaines sur des matrices de plusieurs milliers de lignes. Cross-LoRA fait l'observation duale côté que LoRA fait côté .
- Hypothèse de bas rang du fine-tuning : LoRA lui-même repose sur l'idée que est de faible rang. Cross-LoRA y ajoute que la base de ce sous-espace peut elle-même être réexprimée d'un modèle à l'autre, par projection sur la géométrie dominante.
Conclusion opérationnelle : si l'on observe un transfert qui casse, ce n'est en général pas l'algèbre qui est en cause, mais l'une des conditions précédentes qui n'est pas satisfaite (familles trop éloignées, modules sans correspondance, profondeurs très différentes).
Un mini exemple chiffré
Reprenons le cas concret Qwen2.5-1.5B LLaMA-3.2-3B qui sert de fil rouge à la Partie 2. Pour une couche d'attention q_proj typique :
| Quantité | Source (Qwen 1.5B) | Cible (LLaMA 3.2 3B) |
|---|---|---|
| Nb couches | 28 | 28 |
| 1536 | 3072 | |
| 1536 | 3072 | |
| 16 | 16 | |
| 320 | 320 | |
| - | ||
| - | ||
| - | ||
| - | ||
| - | ||
| - |
Pour ce couple précis, la recolle dimensionnelle est asymétrique () ce qui justifie pleinement le recours à des , non orthogonaux : un Procrustes orthogonal ne peut tout simplement pas opérer entre et .
FAQ
Pourquoi pas de Procrustes orthogonal partout ?: Parce qu'il impose carrée orthogonale, ce qui exige . Cross-LoRA est explicitement conçu pour le cas hétérogène - donc non contraint.
Que se passe-t-il si ? La SVD ne renvoie que directions ; au-delà on ne gagne rien. En pratique on prend .
L'opération est-elle déterministe ? Oui à un signe près : la SVD a une ambiguïté de signe par direction singulière. Comme est insensible à ce signe (il intervient deux fois), la projection finale est bien déterministe.
Et si l'adaptateur source utilise du rank-stabilized LoRA ou du DoRA ? Le squelette de l'algorithme reste valable, mais il faut adapter le facteur d'échelle ( vs ) et, pour DoRA, traiter en plus la composante de magnitude. Cross-LoRA tel qu'écrit cible le LoRA standard.
Ce que dit la pratique
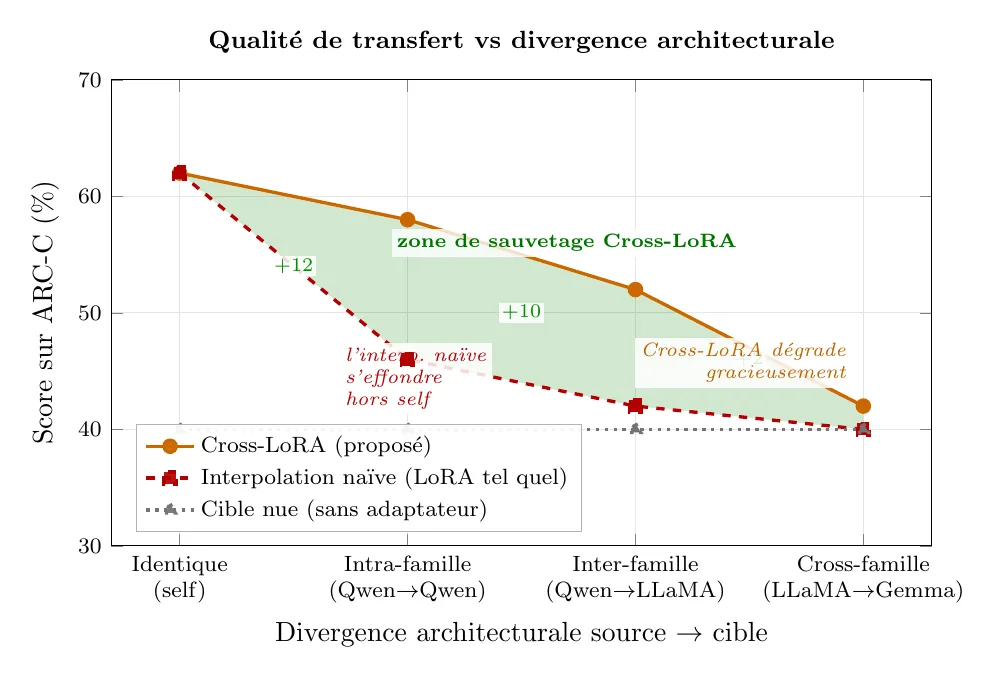
Le papier teste Cross-LoRA sur quatre modèles et quatre benchmarks de raisonnement en QCM :
- modèles de base : LLaMA-3.2-3B, Qwen2.5-1.5B, Qwen2.5-3B, Gemma-2-2B ;
- benchmarks : ARC-C, ARC-E, OpenBookQA, HellaSwag.
La recette est la suivante : on entraîne un LoRA sur le modèle source, puis on applique Cross-LoRA pour produire un adaptateur attaché au modèle cible, et on évalue ce dernier sur les benchmarks - sans aucun ré-entraînement entre les deux modèles.
Trois points de lecture sont essentiels :
- La bonne baseline n'est pas le LoRA original, qui vit sur le modèle source et ne peut pas tourner sur la cible. Les comparaisons utiles sont :
- le modèle cible nu (sans aucun adaptateur) ;
- une interpolation naïve des poids LoRA quand les dimensions le permettent.
- Cross-LoRA n'égalera pas un fine-tuning natif sur la cible - ce n'est pas son objectif. Il vise à préserver une part du gain du fine-tuning source.
- L'écart base-vs-transfert dépend fortement du couple source/cible. Les paires intra-famille (QwenQwen) transfèrent mieux que les pairesinter-famille (QwenLLaMA, LLaMAGemma). C'est cohérent avec l'hypothèse desous-espaces partagés.
L'article 2 reproduira Qwen2.5-1.5B LLaMA-3.2-3B comme cas concret.
Conclusion
Récapitulons ce qu'on a posé :
- les LoRA ne sont pas portables par nature, mais leur structure de bas rang offre une prise ;
- les poids de deux LLM modernes partagent une géométrie dominante qu'on peut exposer via SVD tronquée ;
- on aligne les bases par moindres carrés (LoRA-Align) puis on projette côté gauche et côté droit séparément (LoRA-Shift, Algorithm 1) ;
- l'opération est zero-data, zero-training, et coûte essentiellement quelques SVD plus une résolution de par couche.
Mais entre cette algèbre et un checkpoint PEFT qui se recharge réellement dans le modèle cible, il reste un fossé. Les vraies questions sont d'ordre pratique :
- comment matcher les modules
q_proj,k_proj,v_proj, … entre LLaMA, Qwen et Gemma quand les noms et les conventions diffèrent ? - comment gérer les couples de modèles à profondeurs différentes ?
- comment cacher les SVD pour ne pas les recalculer pour chaque module et ?
- comment valider qu'un transfert n'est pas en silence cassé ?
C'est tout l'objet de la Partie 2 - l'implémentation.